
3½ Years of GO-PEG: Our Experience in Generating Cross-border, High Value Data Sets


In late 2019, a consortium of six partners from five countries set out to create harmonised open datasets and their corresponding metadata in areas such as environment, emergency and disaster management that would span at least five EU countries. In the GO-PEG project (Generation of cross border Pan European Geospatial Datasets and Services), co-funded by the European Health and Digital Executive Agency (HaDEA), we wanted to improve existing data harmonisation methodologies and tools and apply them to create the before-mentioned cross border data sets.
This post summarizes the project and our key takeaways now that the project has ended.
In the beginning: A challenge!
What started this project was that, even 12 years after the INSPIRE directive, it was still very hard to create re-useable, fully harmonised, cross-border data sets. The European Commission recognised this and made a call for consortia to create such data sets as well as the tools required for that, and to inform future processes such as the implementation of the High Value Datasets Act.
Thus, we set out at the beginning of the project with three main goals:
- Identify high-value data sets that we should create through selection of key use cases and their data requirements
- Identify current barriers to the creation of fully harmonised, cross-border data sets, and find technical and methodological solutions for these problems
- Create the actual data sets and publish them so that they are visible in the European data portal
To do this, we applied an iterative approach, measuring the successes and gathering info on new issues in each iteration. As an example, we involved stakeholders to see if they could really use the data sets, or whether they were still missing valuable information.
Use Cases and High Value Data Sets
In the project we evaluated more than 15 use cases, ranging from statistical applications to geologic risk assessment and COVID tracking.

More information on these is available on the project website, so we are going to focus on three here in this article:
Flexible UAV no-fly zones with fAIRport
In 2020, we started the fAIRport project, with the goal of creating a detailed map of no-fly zones for Unmanned Aerial Vehicles (UAVs, commonly known as drones) in Germany. Since this is a very well-defined use case based on European legislation, we decided to bring it into the GO-PEG project and to expand it from one country to as many as we could.
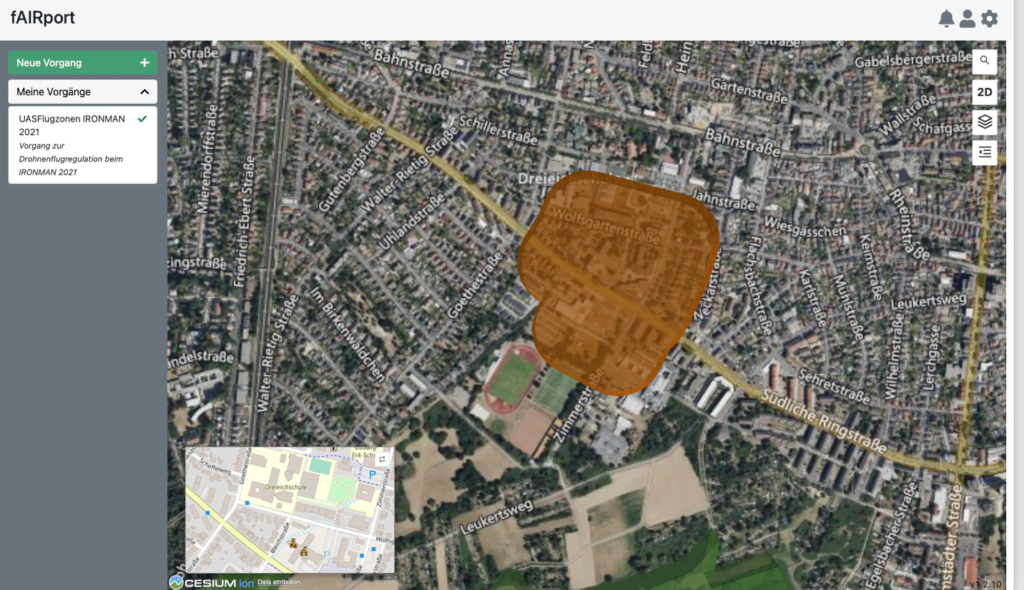
The core idea for the GO-PEG part was to use INSPIRE data, e.g., on transport networks and protected areas, and to transform that to the ED-269 model that is being used in the UAV community to exchange such data. We used hale»studio to do the relevant transformations. To support the required input and output formats, several smaller improvements to hale»studio were made.
No stone left unturned with GO-DEPTH
The GO-DEPTH use case focuses on interoperable, easy-to-use, high-quality subsurface information for sustainable planning and use of natural resources.
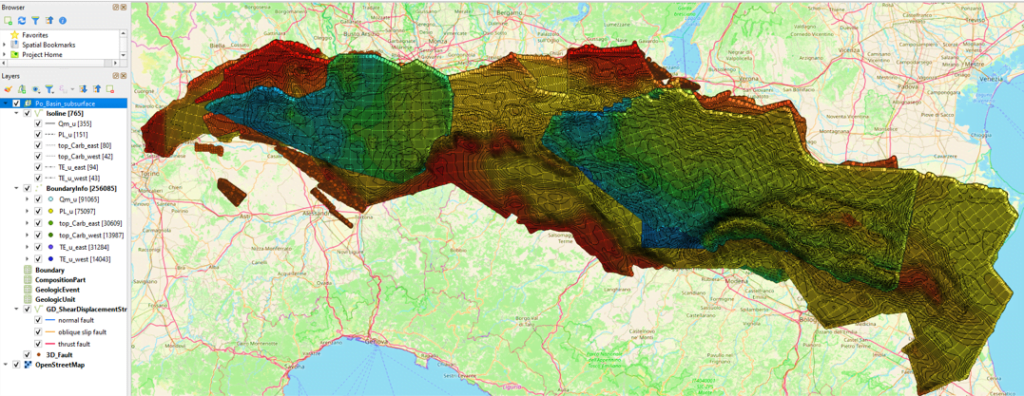
As the use of geological data was particularly relevant to this project, existing data models and code lists were extended. It was also decided to develop a specific GeoPackage logical model for the INSPIRE Geology data theme and test the GeoPackage format as an alternative to INSPIRE default encoding for Geology. After data harmonisation has been completed inside hale»studio, the GeoPackage data set can be shared via OGC API Features.
In short, this project allows you to share easy-to-use, interoperable 3D subsurface information in 4 steps:
- Harmonise to INSPIRE extended model
- Encode in GeoPackage
- Share via OGC API
- Make discoverable in the European Data Portal
Modern solutions for a modern pandemic with geo-COVID Watch
The geo-COVID Watch use case aims to investigate the benefits of geospatial data and edge technologies for a common understanding of the COVID-19 pandemic.
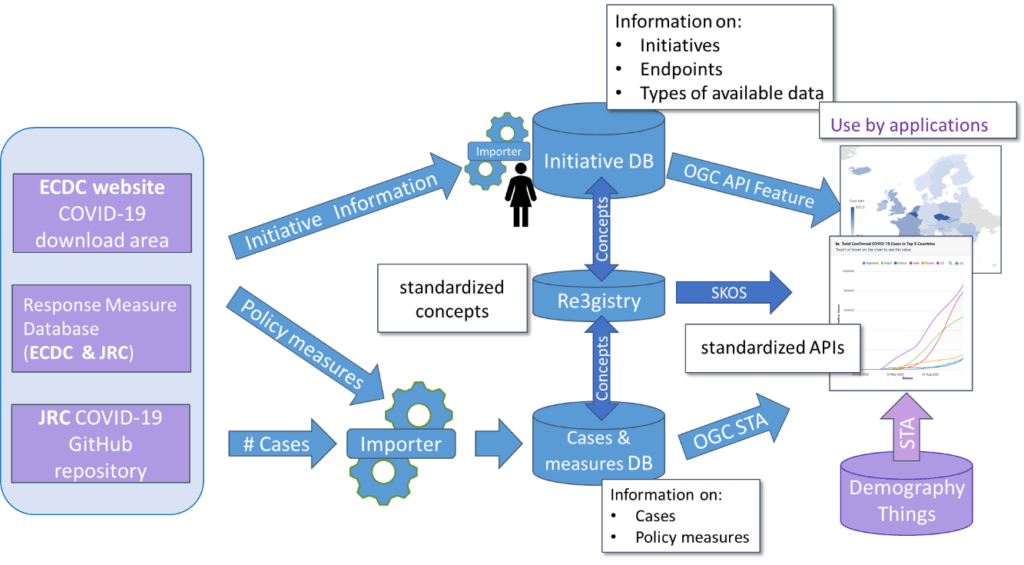
Direct access mechanisms to measurement data, already successfully applied in the environmental field, can be applied to enhance timely availability and interoperability of COVID-19 pandemic data. In particular, the use case investigates the suitability of using OGC standards (Features and SensorThings API) and related technologies for sharing and searching COVID-19 data on the web.
The impact of GO-PEG on hale»studio…
The GO-PEG project was instrumental in the major overhaul and improvement of the Open-Source Software hale»studio. Originally developed in 2008 to 2011, hale»studio has become the most used FOSS ETL tool for geospatial and environmental data in Europe.
Over 99% of hale»studio's users are happy with the product the way it is, so development slowed down from about 2018 to 2020. In 2020, it was clear that the software needed to be updated: It still used Java 8, and many of the libraries and frameworks used were also outdated. While it would have been nice to directly implement the innovations identified to resolve challenges in the GO-PEG use cases, it was clear to us that we should first fix the foundation.
Therefore, we started what should become a work of almost 18 months: Upgrade the software from Java 8 to Java 17 and update pretty much every library and component to the most current versions. After that work was concluded, and hale studio 5.0 was released, we investigated several key innovations such as:
- Automated model transformation
- Mapping Suggestions (a.k.a autonomous mapping, level 3)
For both innovations, we defined a proof of concept and a timebox, in each case of four months. We learned about challenges and approaches that are promising, but all in all, both tools would, at this point, only work for specific schemas, such as INSPIRE or XPlanung.
We have, for the moment, decided not to include these capabilities in the product release. However, if you’re interested in these approaches, reach out to us to learn more.
… and on hale»connect
The other big thing we wanted to innovate on was to finally provide a true INSPIRE-compliant, scalable, and easy to use cloud transformation service. While such services were always foreseen by INSPIRE, there were no production deployments of such a capability. This service should address use cases such as automatically converting data from an alternative encoding to the default encoding for INSPIRE validation, but also cases such as harmonisation to extended INSPIRE schemas.
We decided to build the service by taking hale»studio as well as some components from hale»connect and then built a system based on Kubernetes and Argo Workflows that provides a complete transformation API. While this API is not yet fully compatible to the new OGC API – Processes standard, we aim to complete the missing function soon after the project end. This transformation service has been live for a while now and can be used for a variety of workflows.
Coming to an End
In early 2023, we started the final sprint of the project: Wrap up the development, the documentation and update the data sets, and not to forget: Do the final workshop! That workshop was a true highlight, with more than 180 people attending it.
GO-PEG was definitely a project with an impact. It has helped us to provide you, the community around INSPIRE and other infrastructures, with a modernized high-performance toolkit.
To conclude, I’d like to thank the project team, specifically Danny Vandenbroucke and Marc Olijslagers of KU Leuven, Giacomo Martirano of Epsilon Italia, Anders Östman from Novogit, as well as the groups at Bilbomatica and Geograma!