
Tutorial: Working with Collectors in hale»studio


Collectors are a powerful feature that we introduced in hale»studio 3.1.0 and have since then expanded on. So, for what use cases should you be looking at collectors?
- Your target schema has a collection object, such as a
Network, that needs to reference many or all objects of a different type, e.g.NetworkLinks - You are building up a hierarchy of objects such as
AdministrativeUnits, with theirupperLevelUnitandlowerLevelUnitreferences - You need to use Merge or Join operations to determine relationships between objects, but these are computationally too expensive
With a Collector, you can collect values in one place in your transformation project and then use these values in another place in the transformation process. Let's look at a recent project we've worked on to see how they work in practice.
Please note that this article assumes you have working knowledge of hale»studio and know the terminology.

To use a collector, there are two to three steps:
- Define the collector
- Define where to apply values from the collector
- Optionally, define Cell Execution priorities to make sure collected values are available when used
We always collect values in the context of another transformation function. As of hale studio 3.2.0, these are the transformation functions that support the definition of collectors:
- Groovy Scripts and Groovy Script (Greedy)
- Groovy Retype
- Groovy Merge
- Groovy Join
- Custom Functions
In all of these functions plus the following ones, you can apply the collected values:
- Groovy Create
- Assign Collected Values
With the upcoming 3.3.0 release, you'll see more widespread support for the feature. Basically, most existing functions will allow collecting values, and we'll add more functions to assign them.
The Use Case
This is the use case we are going to work on for this tutorial:
We need to create an INSPIRE Hydrographical Network dataset from UK Meridian 2 data encoded in a specific schema, using a GML 2.1 encoding. Each river segment from the source will be transformed to a
WatercourseLink, and in addition, we'll create aNetworkobject that references all createdWatercourseLinkfeatures.
You can take a look at the hale transformation project for this tutorial and download it, including source data, here at haleconnect.com.
Implementation
Step 1: Define the Collector in a Groovy Script
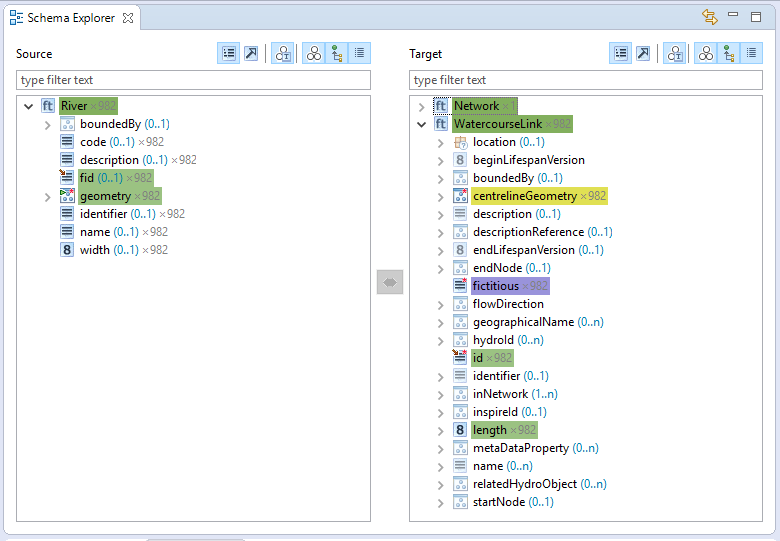
- As always, first define the Type-level transformation function. On the source schema, pick
River, on the target side, selectWatercourseLink. Click on the double arrow icon and selectRetype. Use the default values for the function. - Now, select
fidon the source andidon the target feature type. Click on the double arrow icon and selectGroovy Script. Leave the parameters on the first page as they are and clickNextto proceed to the actual script editor. After you've entered the script, clickFinishto let the transformation execute.
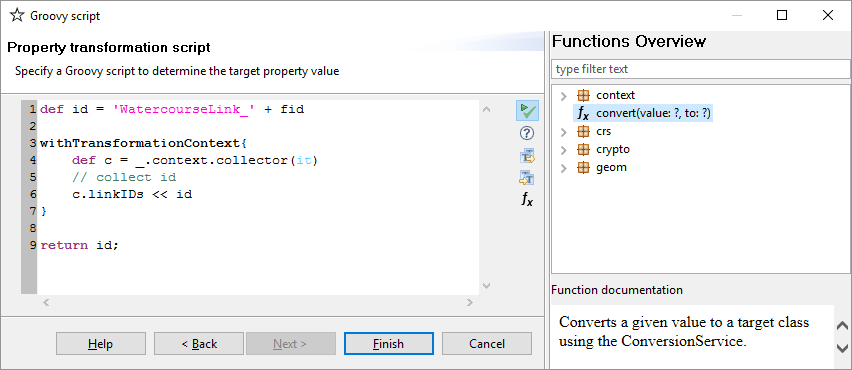
This is the actual script to use:
Step 2: Use the collected values in an Assign collected values function
The easiest way to use values from a collector is to use the Assign collected values function. Follow these steps to use it:
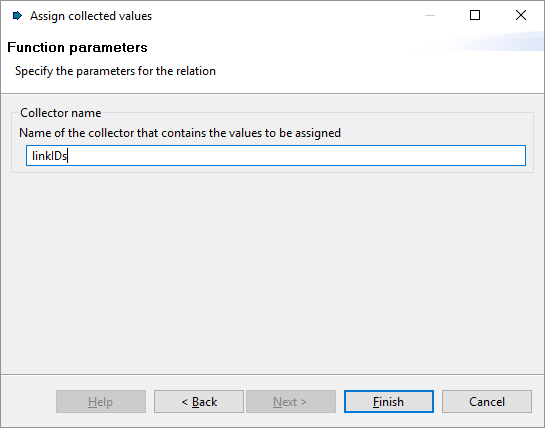
- In the target schema, select the
Networkfeature type. Click on the arrow icon and selectCreate. This function will create one or more objects of the target type from thin air. Create exactly one object. - Next, click on the
elementsproperty inNetworkand then on the arrow icon. ChooseAssign collected valuesand clickNext. Enter the name of the collector we've defined in the script above (linkIDs) so that it can be accessed.
The Assign collected values function has some special behaviour to automatically identify and create local references. If you inspect the created network, you'll see it now has 982 references that all look like this:
Step 3: Transform in the right order
hale studio, in principle, automatically determines execution order of all cells. In some cases, this may not have the desired effect, so you need to provide hints to the transformation engine what should happen first, and what should happen last. For collectors, it's important that the engine first completes collecting values before it tries to apply them in a different place. We do plan to recognize these cases automatically but for now, you'll have to assign cell execution priorities to make sure everything always works as expected.
To ensure that the described steps are executed in the correct sequence, the execution priority has to be defined accordingly. The second mapping cell (Create on Network) has therefore to be set to a lower priority than the first mapping cell. This can be done via context menu in hale studio.

Summary
With these three steps, you learned how to use the collector feature in hale»studio. Let us know what you think of this feature and what we can do to improve its usability!
Happy transforming!