
Building On INSPIRE: The Danube Reference Data and Services Infrastructure (DRDSI) Data Harmonisation Project

INSPIRE Pilots and Data Harmonisation Case Studies
To support the INSPIRE implementation and understanding, the JRC coordinates several large-scale INSPIRE pilot projects, such as the Marine Pilot, the Transportation Pilot and also the Danube Reference Data and Services Infrastructure (DRDSI).
DRDSI is an initiative that aims to provide support for the implementation of the European Union Strategy for the Danube Region (EUSDR) in close cooperation with key scientific partners. The initiative covers a lot of use cases and datasets that are inherently cross border, such as…:
- River Basin District Management
- Assessment of Water Resources
- Environmental Impact Analysis
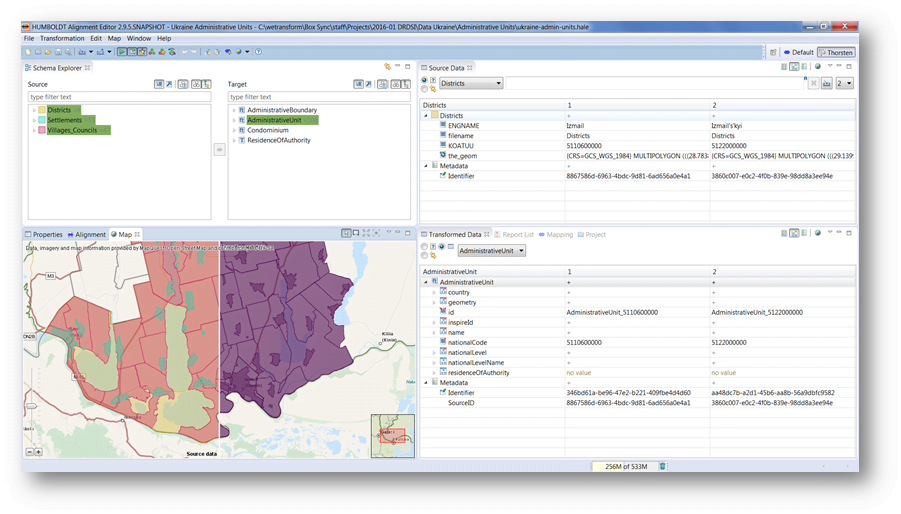
In the scope of the DRDSI project, we implemented a data mapping and transformation pilot. The pilot involved all steps of a data harmonization project, from source data analysis over transformation to data publishing, and was conducted with a short timeframe and relatively small budget. The data harmonisation pilot was commissioned by the JRC and executed by wetransform.
Through this work, we created harmonized data that adds content and value to the existing DRDSI. The work aimed at filling in gaps in regional datasets by creating harmonised data for bordering countries and documenting results for use in the DRDSI platform.
Analysis
As a first step, we wanted to know whether the existing data is fit for INSPIRE harmonisation. We received seven data sets from Moldova and five data sets from Ukraine. For all data sets, we performed a quick quality analysis. This analysis included the following checks:
- Completeness: Are all fields in the source data filled?
- Consistency: Are there many inconsistent values, such as overlapping geometries, or different spellings of the same names?
- Coverage: Can we likely get the minimum required information to fulfill INSPIRE requirements from the source data sets?
- Encoding: Is the encoding clear and correct?
Based on the analysis, we decided to use data sets for three different INSPIRE themes for the pilot: Administrative Units, Hydro-Physical Waters and Railway Transport Networks.
Transformation
In many INSPIRE implementation projects, there are two steps: conceptual mapping and transformation development. With hale studio, both steps can be combined into one. There are several functions we used to make sure we got the mapping right – both conceptually and technically. In particular, we used hale studio’s real time validation features based on the loaded source data to assess whether our target data set is schema compliant. For review of the mapping by the data providers, we generated the interactive documentation and worked on improvements together. You can check out two example transformation projects we created here:
Publishing
When the transformation projects were completed, the next step was to publish the data as INSPIRE View and Download services.
We generally provide two options how to deliver services: Either as Docker Containers, or as public cloud services. As the data providers and research partners in the project didn’t have resources to host the services, we agreed to use haleconnect.com to publish the data sets. However, we also provided instructions on how the project partners could set up services based on degree directly.
Conclusions
The objective of this project was to quickly implement INSPIRE data sets and services to enable cross-border use cases for the Danube Reference Data and Services Infrastructure. We were able to work very effectively with the data stakeholders, who helped us with the analysis and the mapping through their profound understanding of the data. Using hale studio and hale connect, we acquired, analysed, transformed and published 6 INSPIRE data set with a total effort of about 10 person days.